Introducing sqlite-vec v0.1.0: a vector search SQLite extension that runs everywhere
August 1st, 2024 by Alex Garcia
sqlite-vecis a new vector search SQLite extension written entirely in C with no dependencies, MIT/Apache-2.0 dual licensed. The first "stable"v0.1.0release is here, meaning that it is ready for folks to try in their own projects! There are many ways to install it across multiple package managers, and will soon become a part of popular SQLite-related products like SQLite Cloud and Turso. Try it out today!
The first "stable" v0.1.0 release of sqlite-vec is finally out! You can install and run it in multiple different ways, including:
pip install sqlite-vecfor Pythonnpm install sqlite-vecfor Node.js, Bun, or Denogem install sqlite-vecfor Rubycargo add sqlite-vecfor Rustgo get github.com/asg017/sqlite-vec-go-bindings/cgofor Go using CGOgo get github.com/asg017/sqlite-vec-go-bindings/ncrucesfor Go in non-CGO WASM flavorcurl -L https://github.com/asg017/sqlite-vec/releases/download/v0.1.0/install.sh | shif you're feeling brave
First introduced in my previous blog post, sqlite-vec is a no-dependency SQLite extension for vector search, written entirely in a single C file. It's extremely portable, works in most operating systems and environments, and is MIT/Apache-2 dual licensed.
sqlite-vec works in a similar way to SQLite's full-text search support — you declare a "virtual table" with vector columns, insert data with normal INSERT INTO statements, and query with normal SELECT statements.
create virtual table vec_articles using vec0(
article_id integer primary key,
headline_embedding float[384]
);
insert into vec_articles(article_id, headline_embedding) values
(1, '[0.1, 0.2, ...]'),
(2, '[0.3, 0.4, ...]'),
(3, '[0.5, 0.6, ...]');
-- KNN-style query: the 20 closes headlines to 'climate change'
select
rowid,
distance
from vec_articles
where headline_embedding match embed('climate change')
and k = 20;vec0 virtual tables store your vectors inside the same SQLite database with shadow tables, just like fts5 virtual tables. They are designed to be efficient during INSERT's, UPDATE's, and DELETE's. A MATCH constraint on a vector column signals a KNN style search, which is also optimized for speed.
¶ It runs everywhere!
sqlite-vec works on MacOS, Linux, and Windows. It runs in the browser with WebAssembly, in command line tools, and inside web applications on the server. It compiles successfully on Android and theoretically on iOS, I just don't have pre-compiled packages available yet. It works on Raspberry Pis and other small devices.
As proof, here's sqlite-vec running a semantic search demo on my Beepy device, which is a Raspberry Pi Zero.
That demo is a single SQLite file, the all-MiniLM-L6-v2 model in GGUF format (f16 quantization), sqlite-vec, sqlite-lembed, and Python. Not a single byte of data leaves the device.
¶ Only brute-force search for now
Many vector search library have some form of "approximate nearest neighbors" (ANN) index. By trading accuracy and resources for search speed, ANN indexes can scale to ten of millions or even billions of vectors. Think HNSW, IVF, or DiskANN.
But let's be real - most applications of local AI or embeddings aren't working with billions of vectors. Most of my little data analysis projects deal with thousands of vectors, maybe hundreds of thousands. Rarely will I have millions upon millions of vectors.
So sqlite-vec is currently focused on really fast brute-force vector search. And it does extremely well in that regard. And with quantization and other vector compression techniques, you can get really, really far with this approach.
But let me be clear — I'm not ignoring performance in sqlite-vec, and sqlite-vec will eventually gain some form of ANN indexes in the near future (follow #25 for more info). It just didn't make sense to include a complex ANN solution in this initial version.
¶ Quantization and Matryoshka
"Vector quantization" refers to a few techniques to compress individual elements inside a floating point vector. Every element in a float vector takes up 4 bytes of space, which really adds up. One million 1536-dimensional vectors takes up 1536 * 4 * 1e6 byes, or 6.144 GB!
sqlite-vec supports bit vectors alongside "regular" float vectors. These take up much less space — 1 bit per element, a 32x reduction! This does mean a loss of accuracy, but possibly not as much as you expect. Specifically, newer embeddings models like MixedBread's mixedbread-ai/mxbai-embed-large-v1 or Nomic's nomic-ai/nomic-embed-text-v1.5 claim their models are trained on binary quantization loss, meaning a signicant amount of accuracy is maintained even after converting to binary.
To convert a float vector to a binary vector, all you need is the vec_quantize_binary() function:
create virtual table vec_items using vec0(
embedding float[1536]
);
-- slim because "embedding_coarse" is quantized 32x to a bit vector
create virtual table vec_items_slim using vec0(
embedding_coarse bit[1536]
);
insert into vec_items_slim
select rowid, vec_quantize_binary(embedding) from vec_items;Which will assign every element <=0 to 0 and >0 to 1, and pack those results into a bitvector.
The result — depending on your embedding model, possibly only a 5-10% loss of quality, in exchange for ~10x faster queries!
sqlite-vec also supports Matryoshka embeddings! Matryoshka refer to a new technique in embeddings models that allow you to "truncate" excess dimensions of a given vector without losing much quality. This can save you a lot in storage and make search queries much faster, and sqlite-vec supports it!
create virtual table vec_items using vec0(
embedding float[1536]
);
-- slim because "embedding" is a truncated version of the full vector
create virtual table vec_items_slim using vec0(
embedding_coarse float[512]
);
insert into vec_items_slim
select
rowid,
vec_normalize(vec_slice(embedding, 0, 512))
from vec_items;¶ Benchmarks
As always, a disclaimer:
- Benchmarks rarely ever reflect real-world performance
- Every vector search tool is different, and it's totally possibly I use them incorrectly in this benchmark
- These benchmarks are likely skewed to workflows that work well in
sqlite-vec - Benchmarks are highly dependent on your machine and available resources
- Let me know if you find any issues and I will correct it
That being said, if you want to compare how fast sqlite-vec is with other local-first vector search tools, here's a test I ran on my own machine. It mimics running multiple KNN queries sequentially on different vector search tools, to emulate what a "search engine" would do. A few qualifiers to this specific benchmark:
- Only in-process vector search tools are included, aka no external server or processes (no Pinecone, Qdrant, Milvus, Redis, etc. ). Mostly because I don't want to include client/server latencies, and they're harder to set up
- Only brute force vector search is compared. This does NOT include ANN indexes like HNSW, IVF, or DiskANN, only fullscan brute force searches. This is pretty unfair, as not all vector search tools really optimize for this, but it's what
sqlite-vecdoes. And most benchmarks on ANN indexes also care about recall perf on top of search speed, which doesn't make much sense here. - Ran on my Mac M1 mini, 8GB of RAM. In this case the datasets fit into memory, because most of these tools require that.
- Runs queries sequentially and reports the average. Some tools like Faiss could do multiple queries at the same time, but queries here are ran sequentially, to emulate a search engine.
- "Build times" refer to how fast that tool can convert an in-memory NumPy array of vectors into their internal storage. Some tools can read NumPy array with zero-copying, others will need to re-allocate the entire dataset.
The results:
sift1m: 1,000,000 128-dimension vectors, k=20
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Tool ┃ Build Time (ms) ┃ Query time (ms) ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ faiss │ 126ms │ 10ms │
│ sqlite-vec static │ 1ms │ 17ms │
│ sqlite-vec vec0 (8192|2048) │ 4589ms │ 33ms │
│ sqlite-vec vec0 (8192|1024) │ 3957ms │ 35ms │
│ duckdb │ 741ms │ 46ms │
│ usearch numpy exact=True │ 0ms │ 56ms │
│ sqlite-vec-scalar (8192) │ 1052ms │ 81ms │
│ numpy │ 0ms │ 136ms │
└─────────────────────────────┴─────────────────┴─────────────────┘
With 1 million 128 dimensions (sift1m, a small vector dataset), sqlite-vec performs well!
sqlite-vec-scalarrefers to runningvec_distance_l2(...)manually andORDER BYthose results. This is slowest because it relies on the SQLite engine to calculate the topkresults.sqlite-vec vec0stores vectors in avec0virtual table. This is good for OLTP workloads asUPDATE/INSERT/DELETEoperations are fast, and maintains fast queries with chunked internal storage. Build times are slow, as every insert tracks with SQLite transactions and needs to be assigned a chunk.sqlite-vec staticis an experimental feature that directly queries in-memory static blobs. Here we can directly query the contiguously memory block that backs the numpy array (hence the 1ms build time), and KNN queries don't need handle multiple chunks likevec0does. On the other hand, static blobs are read-only, don't support inserts/updates/deletes, and must be kept entirely in memory.
And on a larger, more realistic dataset:
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓ ┃ Tool ┃ Build Time (ms) ┃ Query time (ms) ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩ │ sqlite-vec static │ 1ms │ 41ms │ │ usearch numpy exact=True │ 0ms │ 46ms │ │ faiss │ 12793ms │ 50ms │ │ sqlite-vec vec0 (8192|2048) │ 15502ms │ 87ms │ │ sqlite-vec vec0 (8192|1024) │ 13606ms │ 89ms │ │ sqlite-vec-scalar (8192) │ 7619ms │ 108ms │ │ duckdb │ 5296ms │ 307ms │ │ numpy │ 0ms │ 581ms │ └─────────────────────────────┴─────────────────┴─────────────────┘
This is the GIST1M dataset with 960 dimensions, but only the first 500,000 vectors because otherwise my Mac Mini runs out of memory.
- Here
sqlite-vec staticoutperforms usearch and faiss, though I'd take this with a grain of salt. Anecdotally faiss and usearch typically outperformsqlite-vec, so this may just be a fluke on my machine. - DuckDB struggles with larger dimensions, possibly because each vector could span across multiple pages (pure speculation on my side). DuckDB is also not a "vector database" so I imagine this will improve.
- I'm not sure why Faiss takes so long to build in this case.
And one more internal benchmark: How many vectors can sqlite-vec vec0 tables handle? The benchmarks above hold all vectors in-memory, which is great for speed, but not realistic in many use-cases. So I devised another benchmark where I stored 100k vectors of various dimensions (3072, 1536, 768 etc.) and element types (float and bit), and saved them to disk. Then I ran KNN queries on them and timed the average response time.
The results:
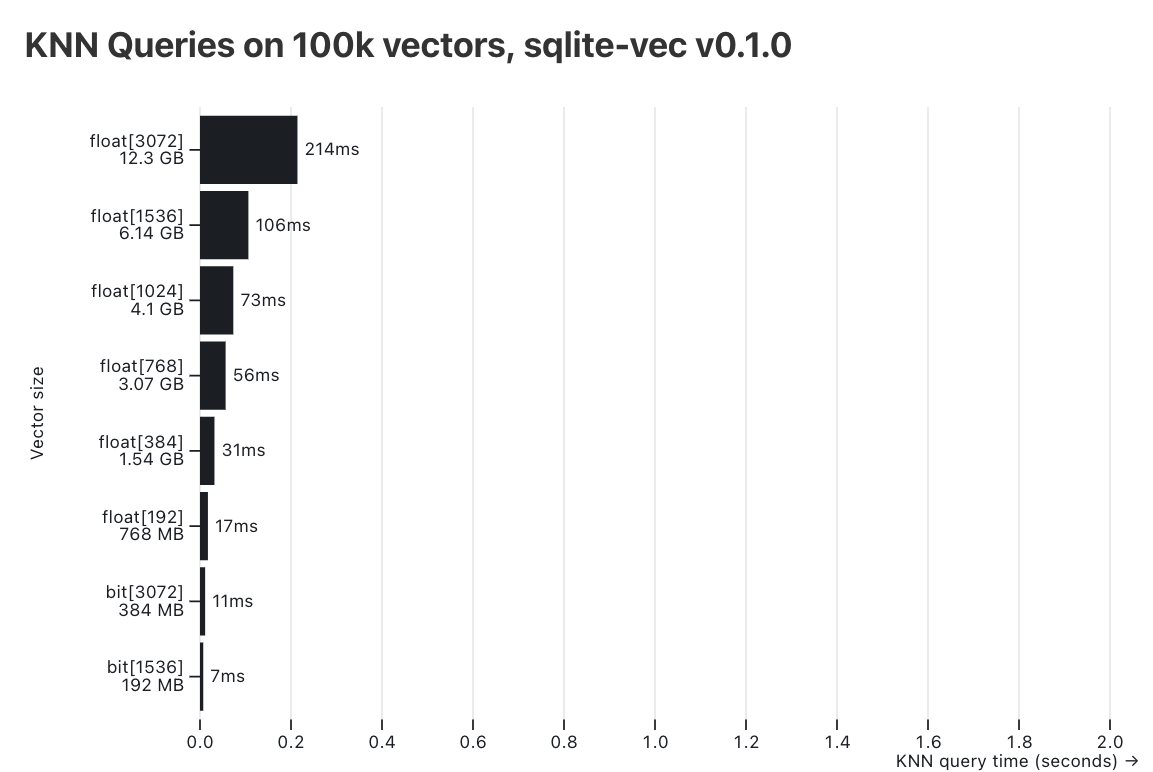
My "golden target" is less than 100ms. Here float vectors with large dimensions (3072, 1536) go above that at 214ms and 105ms respectively, which isn't great, but maybe fine for your use-case. For small dimensions (1024/768/384/192), all response are below 75ms, which is awesome!
For bit vectors the story is even better - even a full 3072-dimensional vector (which is already quite a ridiculous in size) is queried in 11ms, extremely fast. And in this case, where these vectors are from OpenAI's text-embedding-3-large, my anecdotal experience has shown a ~95% accuracy rate after binary quantization, which is fantastic!
However, the limits of sqlite-vec really show at 1 million vectors. The results:
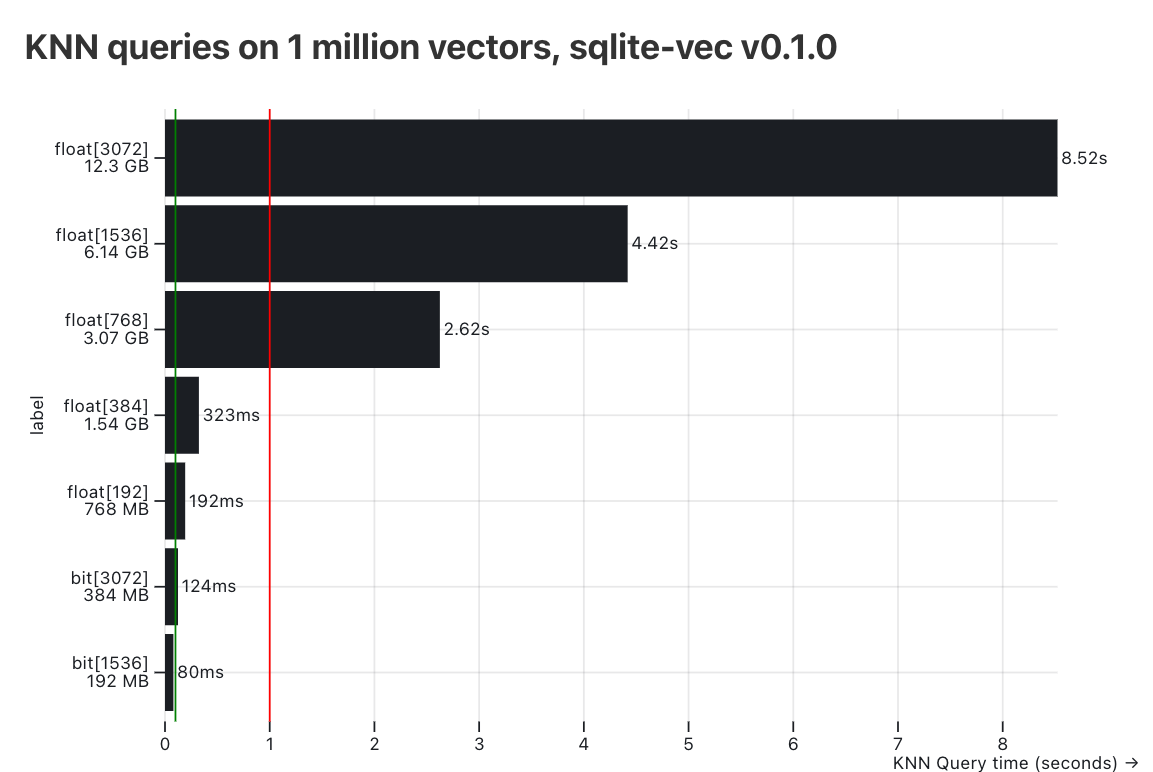
None of the float vectors at any dimension pass the 100ms smoke test — the 3072 dimension vectors take a whooping 8.52s to return, and even the tiny 192-dimensional vectors take 192ms.
However, if you can get away with binary quantization, then 124ms might be an acceptable range for you.
I wouldn't take the exact numbers posted here as the gospel - run different vector search tools on your projects and see what works best. But my takeaway to these benchmarks: sqlite-vec is really fast. Probably not the fastest in the word, but "fast enough" for most workflows you care about. There is definitely a practical limit for latency sensitive applications (probably in the 100's of thousands depending on your dimensions/quantization techniques), but you may not even reach that.
¶ sqlite-lembed and sqlite-rembed sister projects
Vector search is just one half of the equation — you also need a way to generate embeddings from your data. Many inference libraries are quite bulkly and difficult to install, so I created two other SQLite extensions to help tackle this: sqlite-lembed and sqlite-rembed.
sqlite-lembed (SQLite 'local embed'), as announced in the *"Introducing sqlite-lembed" blog post, allows you to generate embeddings from "local" models in .gguf format. sqlite-rembed (SQLite 'remote embed'), as announced in the *"Introducing sqlite-rembed" blog post, allows you to generate embeddings from "remote" APIs like OpenAI, Nomic, Ollama, llamafile, and more. Neither are these are required to use sqlite-vec, and you don't have to use sqlite-vec if you use either of these extensions. But in case you want to keep all your work in pure SQL, these extensions can make your life a bit easier!
¶ Only possible through sponsors
The main sponsor of sqlite-vec is Mozilla through the new Mozilla Builders project. They provide substantial financial assistance, and help build our community with the #sqlite-vec Discord Channel in the Mozilla AI Discord server. I deeply appreciate their support!
Other corporate sponsors of sqlite-vec include:
If your company would be interested in sponsoring sqlite-vec , please reach out to me!
¶ Coming soon to Turso and SQLite Cloud!
Both Turso and SQLite Cloud have immediate plans to include sqlite-vec into their cloud offerings. More about this will be coming soon!
¶ v0.2.0 and beyond
To me, v0.1.0 is all about stability and building a strong core. There are many, many features I have wanted to add to sqlite-vec, but have held off until the basics were down. This includes:
- Metadata filtering! Most applications want to filter a dataset before applying vector search (ie filter between a price range or after a specific date). This is on my immediate roadmap, follow #26 for more info.
- Partitioned storage! Enable per-user or per-document searches, great for single-tenant setups. Follow #29 for more info.
- ANN indexes! Brute force is already really fast, but a custom ANN index optimized for SQLite storage can hopefully get us in the "low millions" or "tens of millions" of vectors range. Follow #25 for more info.
- kmeans for clustering and IVF storage!
- Better quantization methods! Including statistical binary quantization, product quantization, more scalar quantization methods, etc.
- Classifiers! Vector search on embeddings can emulate classification tasks with surprising accuracy, and first-class support in
sqlite-veccan make that much easier
Looking at the very long term, I don't want to be actively developing sqlite-vec for my entire life. I want to get to a stable v1 release in the next year or so, and keep it in maintenance mode shortly after. A "written entirely in C, no dependencies" project can only go so far without becoming an incomprehensible mess, and I care more about building stable and reliable tools than anything else.
So give sqlite-vec a shot! If you have any questions, feel free to post in the #sqlite-vec Discord Channel, or open an issue on Github.